Anomaly Detection¶
The Analysis Package Extension “Anomaly Detection” compares a currently calculated spectrum with a set of reference ones and estimates a difference between them. This way it is possible to detect anomalies in all three spectrum types.
The analysis is based on the autoencoder neural network. First, the reference spectra are collected. Then the neural network is trained on the edge device and stored as a model. Finally, every new calculated spectrum is propagated through that neural network and the anomaly measure (anomaly KPI) is calculated as a mean squared error of the prediction.
It is possible to generate a filtered and un-filtered KPI indicating the anomaly level. For the filtered KPI a buffered window method is applied to reduce sudden outliers, to receive a more clear trending.
Note
The smaller the anomaly KPI, the closer the spectrum to the reference data set.
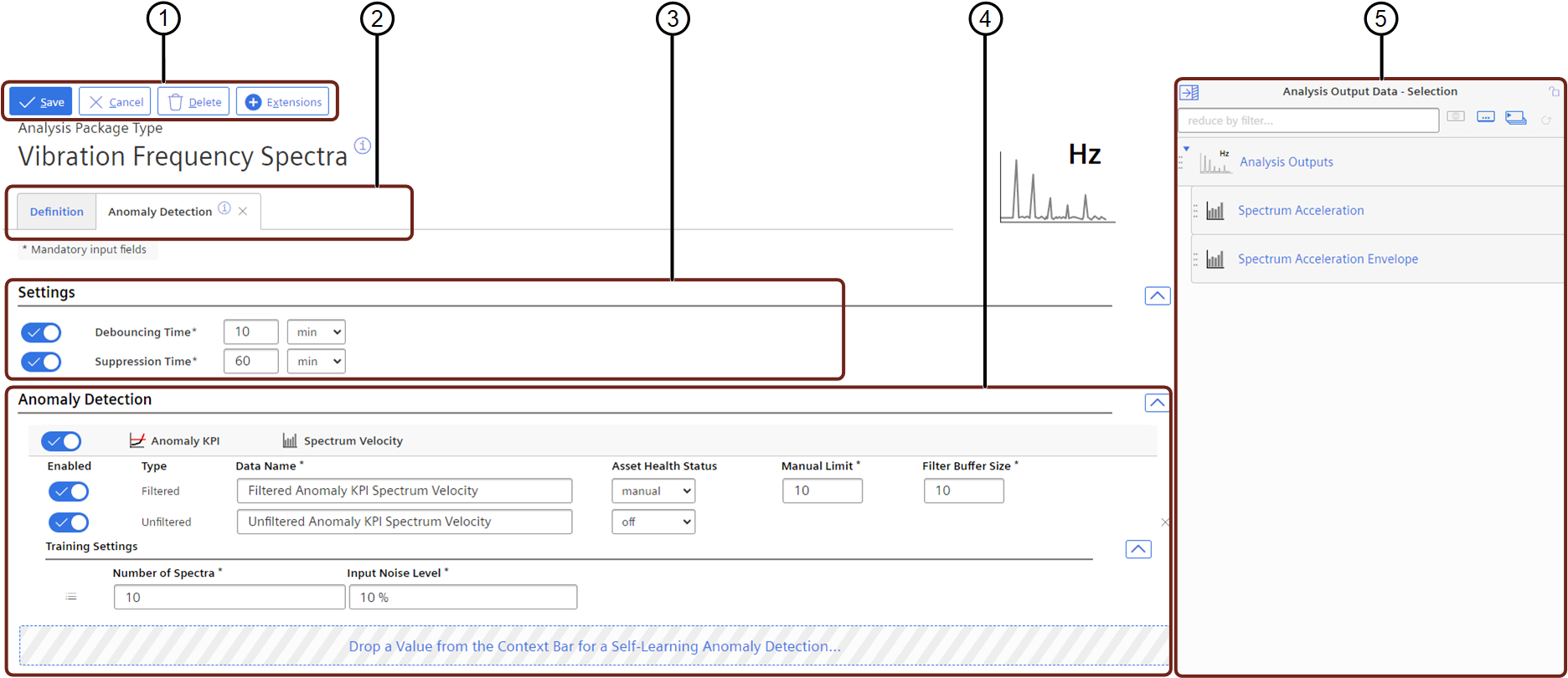
① Save or Cancel settings
② Extension selection tabs
③ Anomaly Detection definitions
④ Context Bar with available spectrum types
| Area | Parameter | Description |
|---|---|---|
| Anomaly Detection | Data Name | Define the anomaly KPI name |
| Asset Health Status | Select the asset health status calculation mode | |
| Asset Health Status Manual Limit | If the asset health status mode is manual, define the limit for the anomaly KPI | |
| Filter Buffer Size | Define the number calculated KPI probes, which shall be collected and used for the filtering | |
| Training Settings Number of Spectra | Define the number of reference spectra collected for training | |
| Training Settings Input Noise Level | Define the level of autoencoder denoising | |
| Training Settings Extended Settings | Open the context bar with extended settings | |
| Context Bar | Analysis Output Data | Shows the available data of the Analysis Package, which can be used for Anomaly Detection |
| Extended Settings Max Iterations | Configure the maximal number of iterations for the training of the neural network | |
| Extended Settings Learning Finished Tolerance | Select the tolerance to stop training of the neural network | |
| Extended Settings Update Mode (in Project only) | Select the update mode |
The Limit Check can also be configured for the anomaly KPI. Apart from the possibility to specify the limit manually, there is another option to estimate this limit automatically. In the latter case, the anomaly KPI is calculated on the reference spectra, and its mean value and standard deviation (stddev) are calculated. The limit is estimated as mean + 4 * stddev.
If a limit is defined, a determination of the health status will be performed, and the settings for debouncing and suppression time are shown and can be set. On exceeding one of these limits, a corresponding health status is generated, uploaded to Industrial IoT, and can be monitored in Insights Hub Monitor.
The debouncing time can be used to suppress the event creation on exceeding limits. If the timeseries data settles back below a previously exceeded limit within the defined time, no event is created.
After an event has been created, further events will be dismissed for the defined suppression time if the suppression is enabled.
When the training process is completed, an optimization report is uploaded as an IoT File to a data asset, where all spectra and anomaly KPIs are stored. The name of the file is built up as <anomaly KPI name>.optimization-report.<version>.txt.
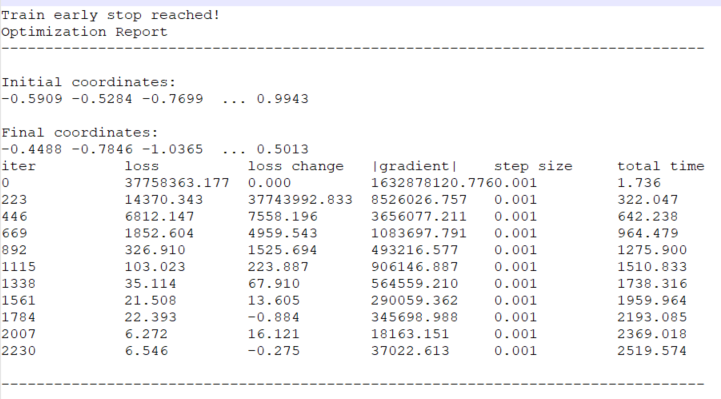
Another source of important information about the training process can be found in the Log information section. Here, more details can be obtained by switching the severity filter to Verbose.
Note
To assess the anomaly detection quality, examine the optimization report. - If the maximum number of iterations is reached, increase it. - If the training stopped too early, decrease the tolerance and set it manually if required. - Then reset or update the model.
The model can be reset by changing the update setting at the analysis extension instance in Project. When the desired option is selected, the project should be downloaded to an edge device again so that the change applies.
Caution
Currently, it is not recommended to configure more than 400 spectra for training in total on one edge device. A larger amount may lead to performance and memory issues.